games104学习笔记
本文最后更新于:2026年3月28日 晚上
动画
面临的挑战
玩家行为是不可控的,要和gameplay互动;实时性;真实性(Motion Matching)
2D动画
精灵动画(Sprite):一帧一帧循环播放
Live2D
把每个图元都分隔,然后各种拉伸的时候可以做出各种动作

每一个部位生成一个图元来控制,非常直观的动画系统,简单又生动

3D动画分类
基于层次的刚体动画,是一个树形结构,但是可能会穿帮,因为只操纵骨骼会互相穿插有可能。

顶点动画,存offerset的texture和法向的texture,然后根据帧数来计算,可以做一些布料或者流体什么的
蒙皮动画
基于物理的动画:衣料、布娃娃系统、IK(反向动力学)
蒙皮动画
蒙皮动画步骤

坐标系的转换,要理解怎么变化的,乘旋转和平移矩阵,每一个骨骼都有自己的Local Space,并且会是一个一直传递相乘的矩阵(正向运动学),比如手指要一直乘各个手臂

骨骼树的起点是胯部(脊椎的最后一块骨头)

可能会加入一些额外的骨骼,比如什么眼球啊,翅膀啊,斗篷,武器,绑定节点(人骑在马上)这些都是用骨骼来驱动的
为了更好地计算移速、离地高度,会加一个root

四足动物的位置如下:

3D旋转数学基础
2d旋转

3D旋转
可以证明任何旋转都可以用xyz旋转等价,也就是欧拉角

但是欧拉角是有很多问题的,首先他顺序乘的不同会导致结果不同

其次欧拉角会有锁死的情况,比如y轴转了90度,这时x轴和z轴是同轴了,那么就两个的旋转等于只有一个旋转了,造成退化的情况。
非常难插值
传递的时候不能直接相乘
并且很难绕着一个任意的轴来旋转
四元数
这时候就要用到四元数(Quaternion)了

没太听懂,到时候仔细研究一下四元数吧
关节与蒙皮

MJm,是从root上一步一步累计的transform矩阵,记住要乘一个自己绑定的时候的逆,然后可能还要乘一个骨骼到世界坐标的transform,一般编程的时候会把这个逆直接存储下来。

因为动画的帧数不够,所以需要插值,NLERP,然后可能要满足最短路径,这样才能看起来比较自然一点,夹角小的时候用NLERP,大的时候用SLEPR

动画压缩
动画一个帧就三十个pose,然后几十个骨骼,每个都要存旋转位移scale,这种时候就需要压缩,因为很多时候他们的数据是不变的

首先不变的值直接干掉,然后可以用keyframe插值,如果插值造成的误差没超过阈值,那么就可以接受。

直接线性插值会对旋转矩阵会比较差,可以用catmull-rom spline
如果浮点数的范围是有限的,可以转成定点数,归一数压缩一下

如果避免error累积,防止出现动画飘来飘去的情况?要更换计算error的方式,直接比较矩阵函数和插值之后的差值其实不太直观,最好的是visual error,但是又不可能真的直接算,所以会在每个joint拿两个垂直的点,然后来计算这个前后的差值。敏感的可以给大一点。

动画制作流程(DCC)
先用低模做,但是在关节地方会多加一点mesh
骨骼绑定
Skinning
一般自动计算权重,但是也可能要手动调整一下
动画制作
Exporting
要注意跳跃的时候root可能会变化,
动画混合
两个动作之间插值,比如走到跑,weight根据速度来变化,要保证两个动作的时间是一样的,这样才能确定是哪一帧

混合空间(Blending Space)
2d空间中,动作不是一维的,所以有可能有些地方动作密(因为觉得这里需要更细腻的表现),然后插值的时候,不可能把全部动作都插值,这时候就需要用到delaunay三角化,其实也就是把每三个点都连成三角形,然后你插值的时候判断是在哪个三角形里面,只插值这最近的三角形的动作。

鼓掌可以有一个mask,某些动作只应用到上半身

Additive Blending
混合之后再叠加一个blend,比如旋转,可以做一直朝着一个地方点头
动画状态机(Action State Machine)
每一个状态也可以是一个动画状态空间

一般还可以是多层状态机,分开独立控制

动画混合树
定义控制变量,暴露给gameplay系统,让他们来改变,然后通过这些变量来选择当前树该选择哪个节点

也可以通过事件来控制,比如切枪(从步枪变成火箭筒)

Inverse Kinematics(IK反向动力学)
ik可能是多解的,所以这时候需要一个指定朝向,相当于再多加一个平面


如果不止两个,有多个关节,该怎么解?(解有无穷多种可能)
首先要判断解空间,考虑最大和最小,并且还有考虑关节的约束度

CCD,不断地翻滚骨头,循环到目标

FABRIK
把末端直接放在终点,这时候那个骨头会突出去,然后把这个作为下一个的起点,最后迭代过去会导致root也有偏差,这时候再backward一遍,把root拉过去,然后一直这样forward和backward迭代,设置一个error误差。
多目标约束怎么办?共同的节点发生变化,可以用雅可比矩阵+逼近的方式。

面部动画
Facical Action Code System

存的是顶点动画,每一个node相对于自然状态的delta,morph target animation
也有些使用骨骼动画,捏脸,眼球,这些需要。
2d的话也可以直接用uv texture
动画重定向
Source Character->Target Character
Source Animation->Target Animation
重定向的时候存的是相对旋转、scale和位移
要根据腰线的高度等比例放缩一下

如果还不行就得用IK
有些时候,如果骨骼数量不一样怎么办?简单的办法就是把数量不一样的地方,按照数量的差异,做一个插值,4->3就是0.3,0.7,然后把插值找到的位置直接认为是少的那个骨骼的终点位置。

也存在一些问题,比如自身穿模,或者没达到效果,因为有些动作是有语义的,比如鼓掌没合手,可以加一些约束

物理
Gameplay框架
事件机制
一般是用观察者模式,需要定义以下三个东西
Event Definition
有一个enum和parament,要做到可拓展,能实时修改
Callback Registration

要考虑事件和回调的线程安全性问题,比如有可能你invoke的时候那个对象已经被销毁了
可以用强引用,保证invoke的的对象一定不被销毁;或这软引用,使用之前先判断是否已经被销毁了。
Event Dispatching
派发,如果来一个事件就直接派发,可能会产生堵塞、或者可能发生链式反应,事件一直会有。
一般会实现一个消息队列,把一帧到来的事件全部收集好,然后下一帧统一执行。
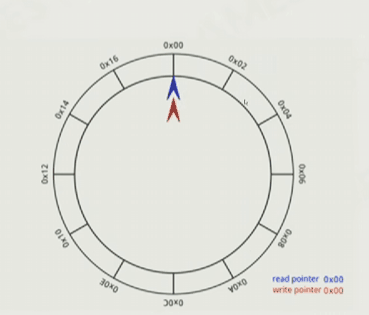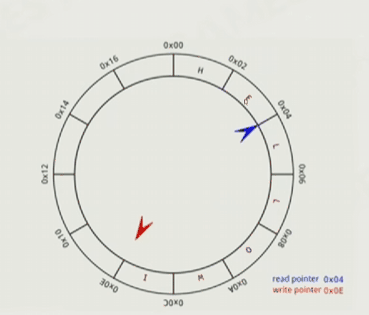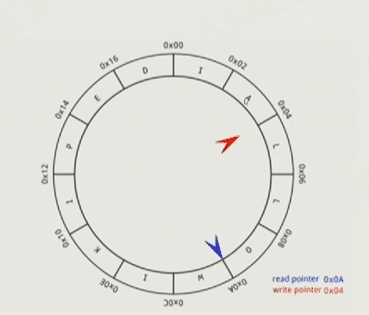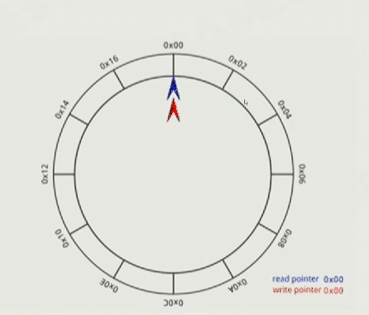
要实现序列化和反序列化,以及Ring buffer,这样就不用重复申请和释放内存,好处是不会崩,顶多是那一瞬间卡一下
不同的类型要分批分发

也会有问题,比如有些事件就需要即时发生;以及delay会一直累积
游戏逻辑和脚本系统
热更新所以得用脚本语言?
GO的管理靠谁来管理?一般是脚本,因为很多跟逻辑相关,一般是靠GC
如果本身对象没有那么多,比如单机游戏,更加注重ai动画,那么就直接引擎来管理
解释性语言可能会比较慢,可以用JIT(一边执行一边编译)
可视化脚本
面向设计师,让他们免于管理生命周期。可视化脚本也要实现编程语言的那些共同的要素。
变量:类型和作用域(管脚不一样,同颜色对同颜色就可以了)

语句和表达式
Control Flow
函数:input,body和return
类:蓝图本身就是一个类
debug:直接可视化一步一步走
3C
Character
各种复杂的状态
Control
处理各种输入设备
细节很多,比如会自动锁定,反馈,多态的输入
Camera
不能穿墙
Camera Effect
Cmmera Manager:会有很多不同视角的相机
寻路(Navigation)
地图的表达;寻路;path smoothing
表达的不同形式
路点网络
类似地铁,但是每次地图变化也改变路网的图,而且npc很容易往中间走

Grid
障碍物可以自动更新,类似于光栅化的方式;
存储空间可能比较浪费;而且很难表达3d的层叠结构(桥上桥下)

寻路网格(Navigation Mesh)
需要用凸三多边形
寻路比较快,内存占用比较低。
生成比较复杂,且不支持3d空间
八叉树
可以表达3d空间

寻路算法
其实不管什么表达方式连接点都可以变成一张图
dfs
bfs
Dijkstra算法
Astar
navmesh里面直接用多边形相交边的中点的欧拉距离

Path Smoothing

funnel算法
从几何理解比较简单
- 创建沿 A* 路径的portal(多边形交线)列表。确保每个portal的点相对于起点以相同的方式存储。您需要知道某个点是在起点的左侧还是右侧。
- 创建一个由三个点组成的“漏斗”:角色的起始位置(顶点)、portal的右侧和portal的左侧。
- 交替更新funnel的左右两侧,每次都使其变窄
- 当funnel的两侧交叉时,请注意不要更新新漏斗的顶点,并将其存储为平滑路径的一部分。

假如创建的funnel里面直接包含了终点,那么直接连过去就行

Navmesh Generation
voxelization(体素化)
先体素化,然后标记出能通行的区域(通过高度差距),然后用洪水算法,从一个最深的点开始判断哪些是可达的,然后再根据这个生成多边形



还可以给navmesh添加flag,比如水陆地,来实现复杂的寻路算法,习性不同的怪物会走不同的路,一般是直接在地图上放flag然后映射到navmesh上面。
tile:大的meshmp可以分隔成多个小的tilie,因为实际游戏中map可能会变
转向系统

需要更自然,先加速再匀速然后减速
群体模拟
微观的方法,定义每个个体的规则
鱼群效果:远离、接近和跟随

宏观

两者结合,比如说蜂群,多个结合成一个小团体,有一个大趋势,然后团体内部每个个体有自己的规则
如何避免碰撞?
直接加斥力or方向场
RVO
计算别人的速度向量是否在自己的路径上,如果在路径上就各自调整速度向量
感知
自身信息
位置、HP
地形信息:寻路、战术信息、可交互物体、掩护点

动态数据:影响力图,动态寻路数据、视线图、游戏中的object(它身上的各种信息)
视觉感知、听觉感知
AI
状态机

状态太多就不好处理,可以分层,但是不太好飞线

行为树
Sequence
所有子节点依次执行,每个都要执行
Selector
一直试,直到某个节点成功完成
Parallel
同时执行所有节点
比如一边走向目标一边开枪
Decorator
有各种判断条件,以及loop,time这种
Blackboard
行为树的各个节点直接互相通信,存储一些变量
没有目标,只是遇到情况就来判断做什么
层次任务网络(HTN)


首先要定义task:primitive task(原子性任务),要有前置条件,动作和产生影响(effect)
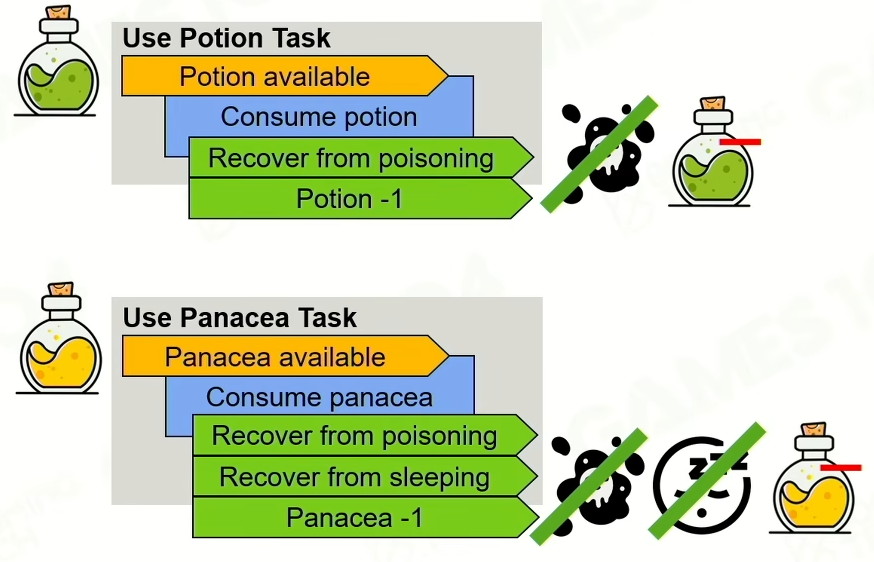
复合任务:会有多个条件,根据优先级哪个满足做哪个,类似行为树的selector,method也可以是复合行为,类似行为树的sequence。
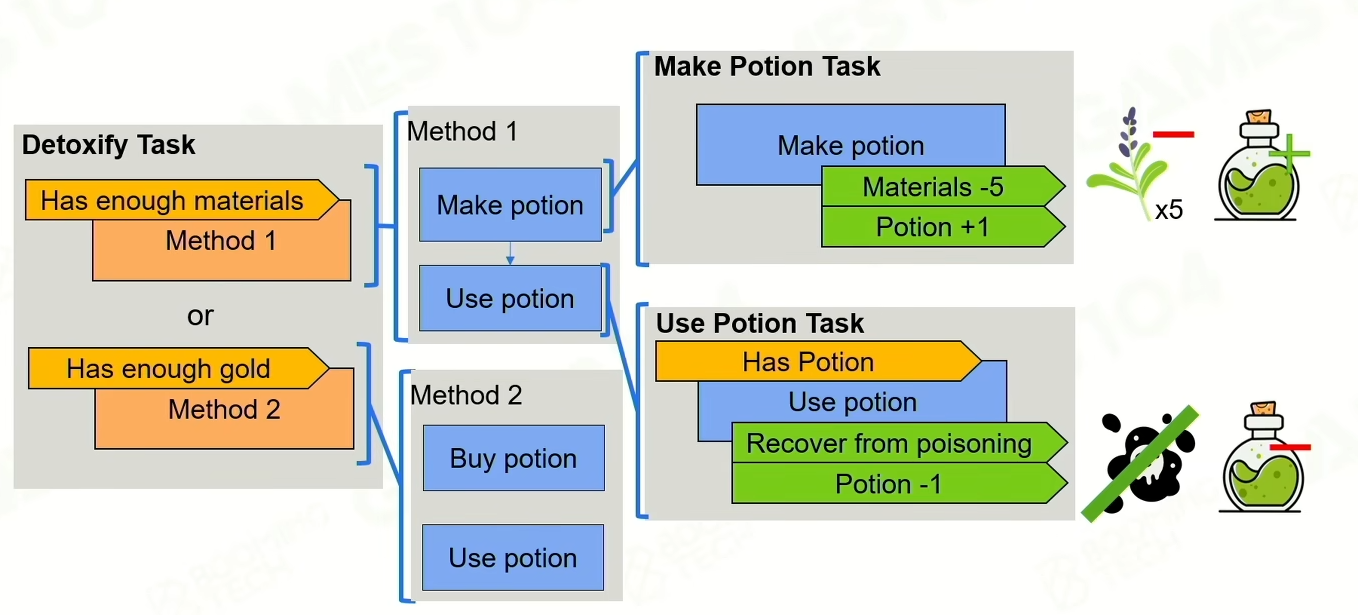
HTN Domain

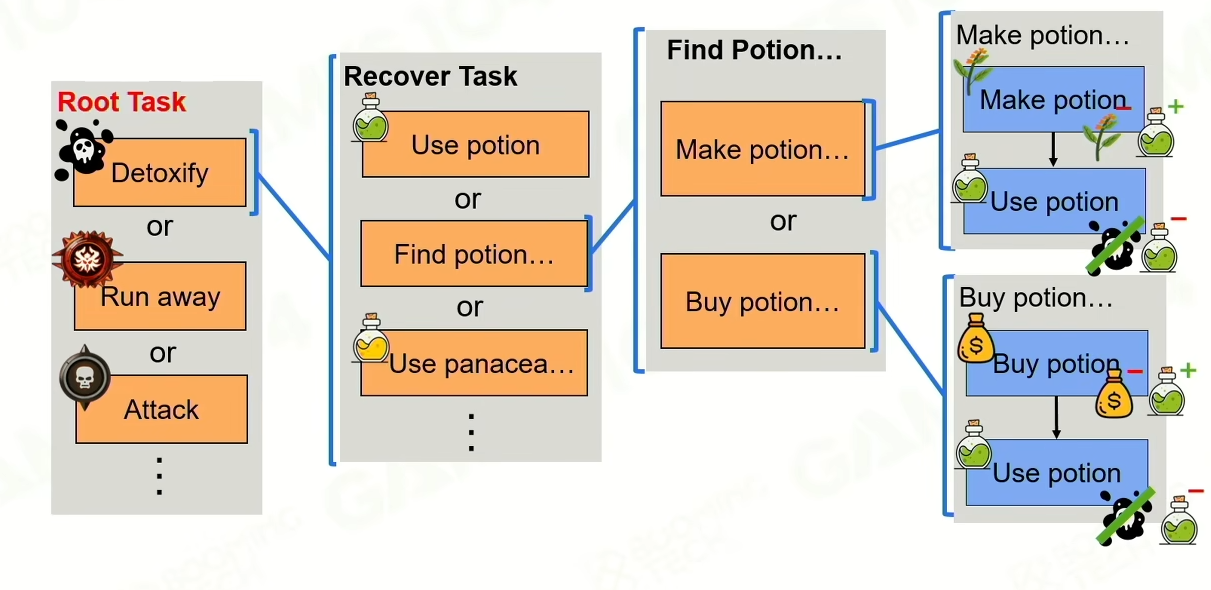
Planning
根据world state的各种propety,来选择做哪个method,计划的时候根据当前的world state来做假设,拷贝一份,但是会假设能做的action都能成功,这里是有可能会有问题的。
Replan
计划失败了需要计划
会更快,plan会有长期影响
行为是不可预测的,会对本身world state有状态变化
目标导向行为规划(GOAP)
多了一个目标集,HTN里面只是写在了注释里面

goal会有precondition和目标state
Action加了一个cost,比如路径的远近,风险,这个需要策划凭借经验来填

state满足的情况下,cost要尽可能地小
